
The general process is:
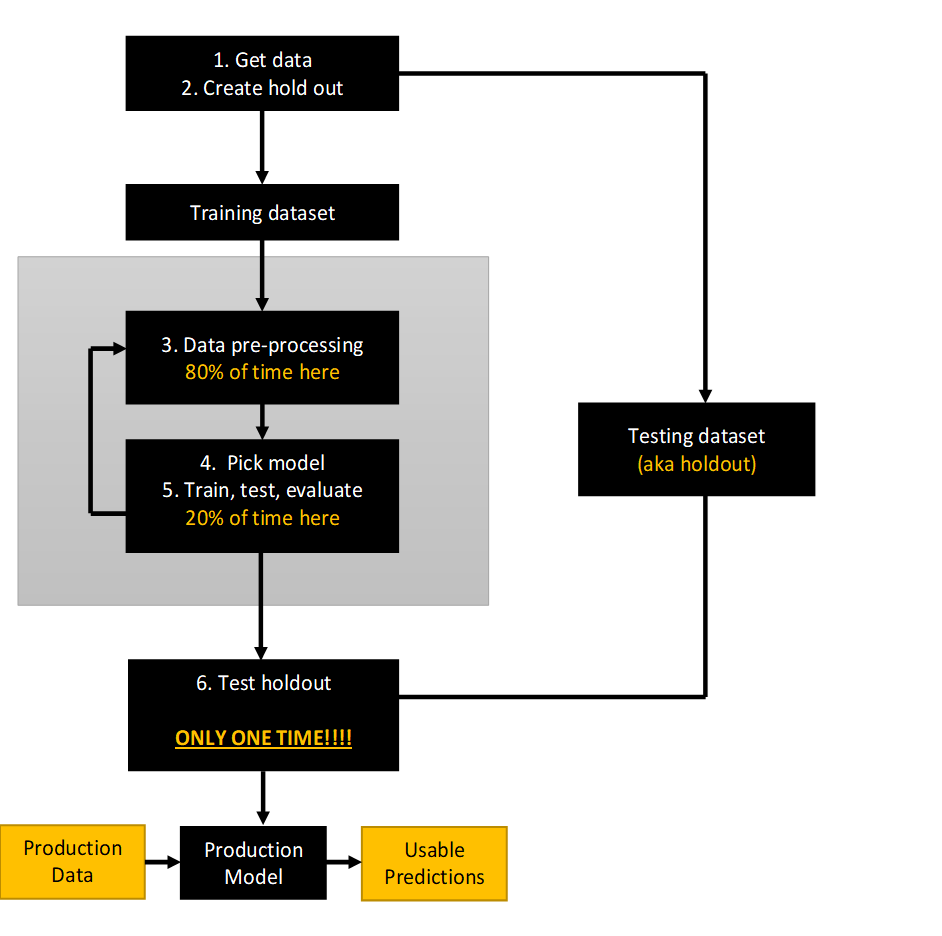
Let's work backwards in discussing those steps.
The objective of machine learning
Basically, ML tasks tend to fall into sets of tasks:
- Prediction accuracy (e.g. of the label or the group detection)
- Feature selection (which X variables and non-linearities should be in the model)
And for both of those, the idea is that what the model learns will work out-of-sample.
The key to understanding most of the choices you make in a ML project is to remember: The focus of ML is to learn something that generalizes outside of the data we have already!
Econometrically, the goal is to estimate a model on a sample (the data we have) that works on the population (all of the data that can and will be generated).
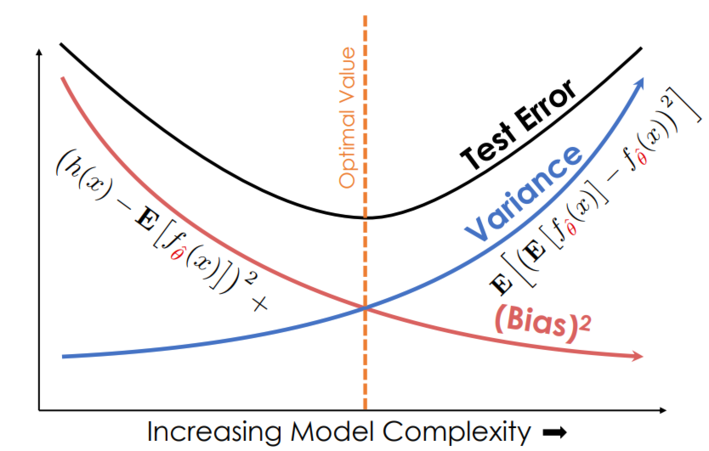
The bias-variance tradeoff
It turns out we can decompose the expected error of a model like this:
\begin{align} E[\text{model error risk}] = \text{model bias}^2+\text{model variance}+\text{noise} \end{align}_(If you want to see the derivation of this, you can go to the wiki page or DS100. The former's notation is a little simpler but the latter is more helpful with intuition)_
"Model bias"
- Def: Is errors stemming from the model's assumptions in how it predicts the outcome variable
- It is the opposite of model accuracy
- Adding more variables or polynomial transformations of existing variables will usually reduce bias
- Removing features will usually increase bias
- Adding more data to the training dataset can (but might not) reduce bias
"Model variance"
- Def: Is extent to which estimated model varies from sample to sample
- Adding more a new parameter (variables, etc) will usually increase model variance
- Adding more data to the training dataset will reduce variance
Noise
- Def: Randomness in the data generating process beyond our understanding
- To reduce the noise term, you need more data, better data collection, and more accurate measurements
To decrease bias and variance, however, we must tune the complexity of our models.
THE FUNDAMENTAL TRADEOFF: Increasing model complexity increases its variance but reduces its bias
- Models that are too simple have high bias but low variance
- Models that are too complex have the opposite problem
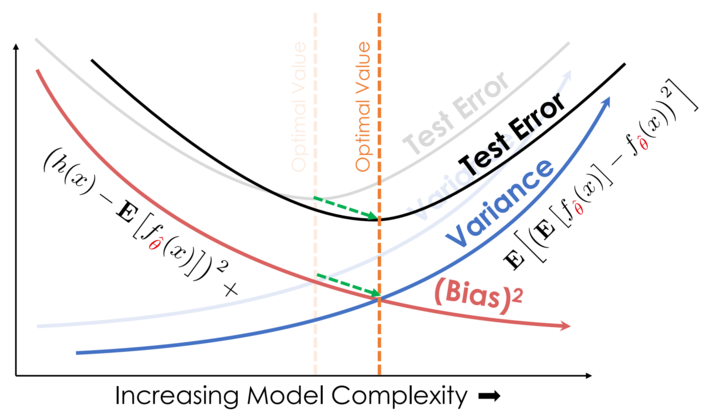
- Collecting a TON of data can allow you to use complex models with less variance
This is the essence of the bias-variance tradeoff, a fundamental issue that we face in choosing models for prediction."
_(This is adapted from DS100)_
Visually, that is
| (A) The classic bias-variance tradeoff | (B) Adding more data reduces variance at each level of complexity |
 |  |
- Models that are too simple are said to be "underfit" and this is usually caused by bias
- Models that are too complicated are said to be "overfit" and this is usually caused by variance
Minimizing model risk
Our tools to minimize model risk:
- More data
- Feature engineering (adding, cleaning, and selecting features; dimensionality reduction).
- Model selection
- Model evaluation via cross validation (CV)
You should absolutely read this on feature engineering, and this for model selection.
Let's dig into CV here because it gets at the flow of testing a model:
Model evaluation via cross validation (CV)
Holdout sample
So we need a way to estimate the test error. The way we do that is by creating a holdout sample (step #2 in the flowchart above) to test the model at the end of the process.
YOU CAN ONLY USE THE HOLDOUT SAMPLE ONCE! If you use it during the iterative training/evaluation process, it stops being a a holdout sample and effectively becomes part of the training set.
Then, in the flowchart, we enter the grey box where all the ML magic happens, and pre-process the data (step #3).
Training sample
So, we have the holdout sample and the training sample.
If we fit the model on the training sample, and then examine its performance against the same sample, the error will be misleadingly low. (Duh! We fit the model on it!)
It would be nice to have an extra test set, wouldn't it? So, we split our training set again, into a smaller training set and a validation set.
- We estimate and fit our model on the training set
- We estimate the error of our model on the validation set
Train-validate-holdout: How big should they be?
Depends. Commonly, it's 70%-15%-15%.
K-Fold Cross-Validation
Problem: 70% and 15% might not be enough training data.
Solution: K-Fold Cross-Validation. Take the 85% of the sample that isn't the holdout and split it up into a training and validation set, fit the model, and test it. Then repeat that by dividing the data into a new training/validation split. And repeat this $k$ times.
Here, it looks like this:
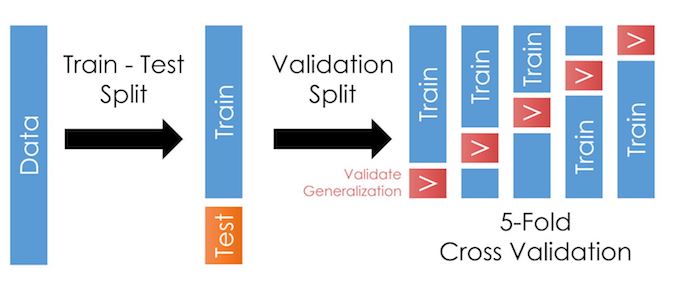
Summary of CV
- Separate out part of the dataset as a "holdout" or "test" set. The rest of the data is the "training set".
- Start steps #3-#5 of the flowchart.
- Split the "training set" up into a smaller "training" set and a "validation set".
- Estimate the model on the smaller training set. The error of the model on this is the "training error".
- Apply the model to the validation set to calculate the "validation error".
- Repeat these "training-validation" steps $k$ times to get the average validation error.
- The model that has the lowest average validation error is your model.
- Test the model against the holdout test sample and compute your final "test error". You are done, and forbidden from tweaking the model now.
Evaluating models
How do you measure accuracy of predictions or the model's fit? There are more, but the most common statistics to report are
| Measurement | Measures |
|---|---|
| R2 | |
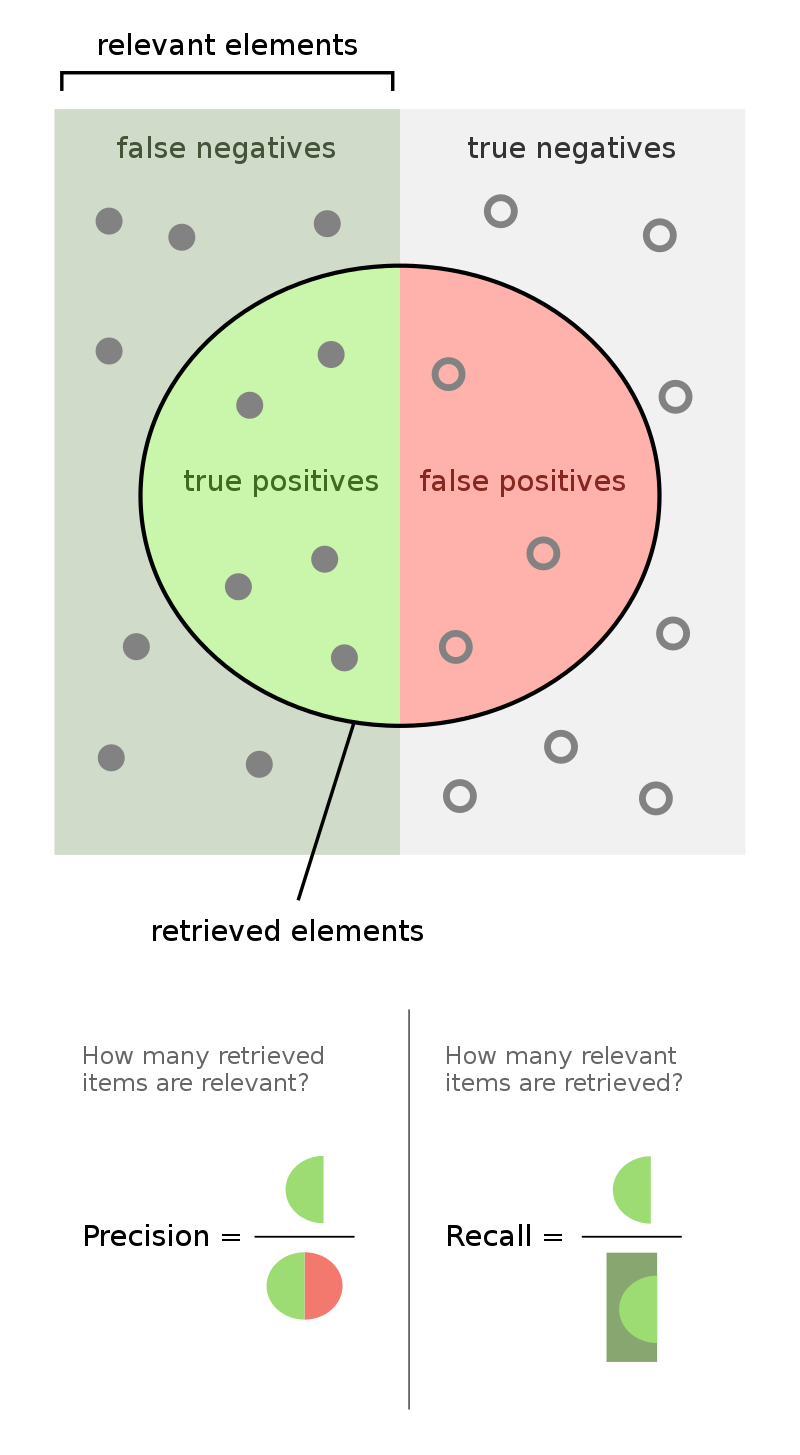
| True Positive Rate (TPR) aka "Sensitivity" aka "Recall" = 1-FNR | What fraction of the true positives do you call positive? |
| True Negative Rate (TNR) aka "Specificity" = 1-FPR | What fraction of the true negatives do you call negative? |
| "Precision" | How precise are your positive labels? What fraction of what you labeled positive are truly positive? |
| "Accuracy" | What fraction of predictions made are correct? |
| False Positive Rate (FPR) = 1-TNR | What fraction of the true negatives do you call positive? |
| False Negative Rate (FNR) = 1-TPR | What fraction of the true positives do you call negative? |
| F1 | Combines recall and precision |
If you're a visual person, the figures below might help. In the figure below, your classifier calls the objects in the circle positive, the left half are true positives, and the right half are true negatives.
 |  |
Which measurement should you use?
It depends! You have to think about your problem:
- In medical testing, false negative is really bad, so tests tend to focus on minimizing false negatives at the expense of increasing false positives.
- In the legal field, false positives (imprisoning an innocent person) are considered worse that false negatives.
- Identifying terrorists? You might want to maximize the detection rate ("recall"). Of course, simply saying "everyone is a terrorist" is guaranteed to work! So you also should think about "precision" too. Maybe F1 is the metric for you.
Model selection
Step #4 of the flowchart. You need to pick the right model for your job. One way to pick amongst the possible options is to consider whether or not you need a supervised model.
A dichotomy of ML models
Supervised learning models, try to predict "labels" (you can think of these as $y$ values) based on training data that already has the $y$ variable in it ("labeled data"). E.g.,
- Regression: Predicting continuous labels
- Classification: Predicting discrete categorical variables (two or more values)
Unsupervised learning models, build structure on unlabeled data. E.g.,
- Clustering: Models that detect and identify distinct groups in the data
- Dimensionality reduction: Models reduce the number of "features" (variables)
The PythonDataScienceHandbook has a nice introductory list of example applications for ML techniques, and the sklearn example page has a rather comprehensive set of examples with code!
Required reading
- This on feature engineering
- This on model selection
- Peruse/skim the examples here
- Peruse/skim the examples on the sklearn site, which come with code