
Golden Rules for Projs and Progs
The goal of this class is to give you a set of rules, guidance, and some hard-earned wisdom to help you write better programs and develop better projects. I've spent more hours of my life fixing bad programs and issues caused by project management mistakes than I have spent watching the Detroit Lions be awful. So, please, let me help you avoid that tragedy! Don't let the Lions OR bad project/program habits ruin your Thanksgiving!
BUT FIRST! I want to do a status check and see what can be addressed. Please click your class time: 1:35pm section or 3pm section.
.
.
.
.
.
.
.
.
.
It turns out that the issues I allude to above are not unique to me. Economists, financiers, social scientists, and researchers that are trained outside of software engineering or computer science are often (especially early on in careers) unaware of solutions those fields solved for problems that social scientists are only now (at least to them) just facing. It's very common, for example:
- You can't replicate an early version of analysis because it calls functions that have been moved.
- You want to change your sample for tests #4-#12 (in an analysis with 15 test), but the code that defines the sample has been copied and pasted throughout our project directory, and making the change requires updating dozens of files. Turns out, there were copy and paste errors, so those tests didn't even use the same sample!
- You return to a project after weeks (or months...) (or years...) away. Despite all the documentation and comments you left behind, it takes days just to figure out how to run the analysis again.
I love this line from a document this lecture is heavily based on:
Here is a good rule of thumb: If you are trying to solve a problem, and there are multi-billion dollar firms whose entire business model depends on solving the same problem, and there are whole courses at your university devoted to how to solve that problem, you might want to figure out what the experts do and see if you can't learn something from it.
A case study in bad research
We start with an absolutely essential question: Are characters in Game of Thrones more likely to die when they head north or south?
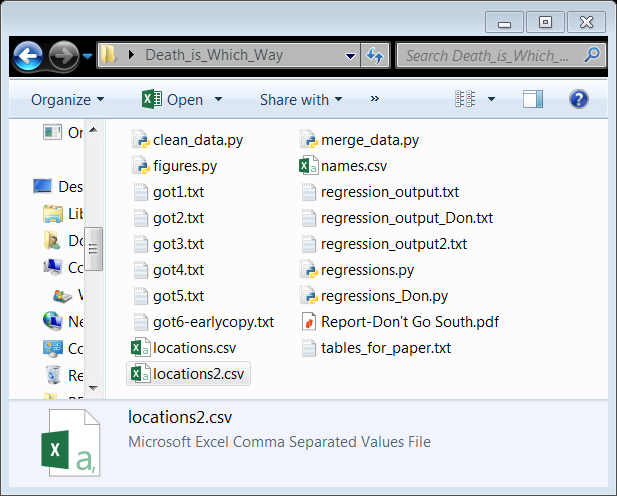
One folder: A "common" data science project
So I collected the text of the (currently 5, COME ON GEORGE) books. I also collected data on the names of characters so I can identify them in the text. I also collected data that maps the names of places to latitudes on the map. I have just about everything I need. I put these files in a folder, write some code to deal with data, and some code to produce output.
There were definitely intermediate steps, but I don't remember exactly. Luckily, this project wasn't "interactive, point-and-click in Excel" analysis. It was written in code! So it's oooooobviously reproducible.
Let's all look at the folder and try to figure it out? What do you think each file is, and how is the analysis conducted from data-to-draft?
.
.
.
.
.
.
.
.
.
.
And no, this isn't a joke - I've definitely seen "professional" researchers with project organized like this in one way or another.
What are the possible issues with this?
- Which data file(s) are the real input?
- Do we run
clean_data.pyormerge_data.pyfirst to build the analysis sample? - Do we run
figures.pyorregressions.pyfirst? - Wait, maybe it's actually
regressions_Don.pythat we should run! - Clearly,
regression_output.txtcomes fromregressions.py(I hope!) andregression_output_Don.txtcomes fromregressions_Don.py.... But where on Earth didregression_output2.txtget conjured from? - Speaking of mysteries, where the %^#! did
tables_for_paper.txtcome from? No python file mentions tables! - Oh god, I just noticed two location files. I guess they are from different sources... but which is used by which files?
So, let's see if we can't improve this whole situation.
THE GOLDEN RULES
| Category | Rule |
|---|---|
| 0. PLAN BEFORE YOU CODE | A. "Pseudo code" is writing out the broad steps in plain language. I often (almost always for complicated tasks) do this on paper, then translate it to code as an outline (in the code's comments). Maybe planning sounds boring and like a waste of time. I get it; I also want to shoot first like Han did... but coders like Han often end up looking like this guy... |
| B. Break the problem into chunks/smaller problems. This dovetails with rule 5.B below nicely. |
|
| 1. Automation | A. Automate everything that can be automated, don't do point-and-click analysis! |
| B. Write a single script that executes all code from beginning to end | |
| 2. Version control | A. Store code and data under version control. Revisit the GitHub workflow recipe as needed! |
| B. Before checking the directory back in, clear all outputs and temp files and then run the whole directory! (Check: Did it work right?) |
|
| 3. Directories | A. Separate directories by function |
| B. Separate files into inputs and outputs | |
| C. Make directories portable | |
| 4. Keys / Units | A. Store cleaned data in tables with unique, non-missing "keys" |
| B. Keep data normalized as far into your code pipeline as you can | |
| 5. Abstraction - fncs/classes | A. Abstract to eliminate redundancy |
| B. Abstract to improve clarity | |
| C. Otherwise, don't abstract | |
| D. Unit test your functions! | |
| E. Don't use magic numbers, define once as variables and refer as needed | |
| 6. Documentation | A. Is good... to a point |
| B. Don't write documentation you will not maintain | |
| C. Code is better off when it is self-documenting |
The effect of the golden rules
Let's apply those rules to our cursed analysis of character death in Game of Thrones and see if this makes the project easier to replicate (in terms of accuracy and time required).
(Note, there are other ways to efficiently divide up analysis than what I propose here that have merit! Do not take this exact scheme as "gospel".)
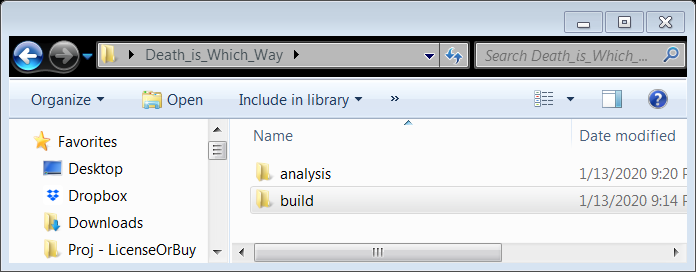
I’ve split the project into two sub-directories: "build" (whose function is to build the sample from the raw data inputs) and "analysis". These are two-sub tasks of any data project, and here, I've chosen to treat them as different functions and thus they get different folders (Rule 3.A).
.
.
.
.
The build folder takes "inputs", which are processed by files inside "code", and places the analysis sample (now explicitly created!) in "output". Notice the inputs and outputs are clearly separated! (Rule 3.B) Temp files are created along the way, but are not "output".
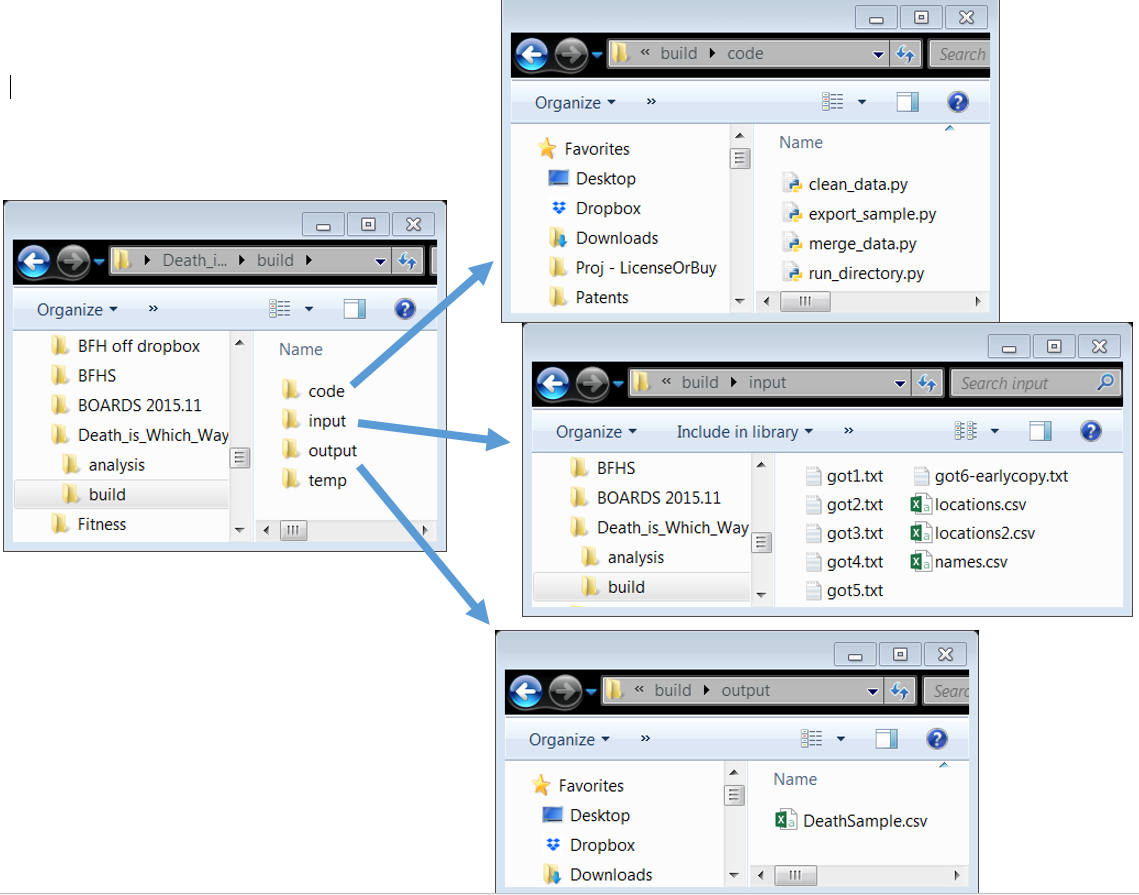
Also, notice the new file run_directory.py. It very quickly and plainly documents how to run the entire code in the "build" project (Rule 1.B), and makes it easy to do so every time (Rule 2.B) before you push it back to the master repo on GitHub (Rule 2.A). run_directory.py is so simple, it is self-documenting (Rule 6.C).
# to create DataSample.csv:
clean_slate() # deletes all temp files and all output files
execfile(clean_data.py)
execfile(merge_data.py)
execfile(export_data.py)This project also obeys Rule 3.C (Make directories portable). Originally, when clean_data.py wanted to load the inputs, it used C:\Users\Desktop\Death_is_Which_Way\build\input\got1.txt. But if our fearless TA tried to execute this file, it wouldn't work! (His Mac doesn't even have a C drive!)
Now, clean_data.py loads ..\input\got1.txt. The ..\ tells it to look "one level up", then inside the input folder. (Aside: You can go up two levels with ..\..\ and so on...)
Good Data: Distinct Keys + Variables at Key's Unit-Level = Normalized
There are multi-billion dollar firms whose entire business model depends on storing and accessing data. Therefore we should apply our rule and see how they store data:
Long ago, smart people figured out a fundamental principle of database design: that the physical structure of a database should communicate its logical structure.
How does that work?
- Every database contains "elements" or "observations" (rows) and "variables" (columns).
- The "key" is the variable(s) that identifies a row in the table.
GMis the key for the observation about General Motors in a dataset whose unit is a firm.(GM, 2000)is the key for the observation for GM in 2000 in a firm-year dataset.- Keys should never be missing! (Rule 4.A) If one is, how can you say what that row is?
- Keys should never be duplicated. If one is, your database won't have a logical structure any more.
- Closely related to "keys" is the idea of "units", refers to the level of aggregation in the dataset.
- Variables in the dataset should apply as properties of the "unit" of the "key". In other words: variables are attributes of the key.
- County population is a property of a county, so it lives in the county database, not the state database. State population is a property of a state, so it cannot live in the county table.
- **Implication: You need one dataset for each unit level. For example:
- One firm-level dataset and one firm-year dataset.
- One county dataset and one state dataset.
If you have distinct keys in your dataset, and all variables apply to the unit of the key, your dataset is said to be "normalized". Storing normalized data means your data will be easier to understand and it will be harder to make costly mistakes. (See the example below)
I doubt you will ever run a serious regression or analysis on completely normalized data. So at some point you will combine the datasets. Do your best to delay that (4.B).
Example: Bad and Good Data
So, as a trivial example, here is a bad firm-year dataset:
| Firm | Year | Profits | First_year | IndustryDef | SubIndustryDef | Profits_Ind |
|---|---|---|---|---|---|---|
| GM | 2000 | 5 | 1908 | 1 | 1A | 1 |
| GM | 2001 | 5.5 | 1 | 1A | 13 | |
| Ford | 2000 | -4 | 1903 | 2 | 1A | 1 |
| Ford | 2001 | 7.5 | 1903 | 2 | 1A | 13 |
| Ford | 2002 | 8 | 1903 | 2 | 1A | 23 |
| 2002 | 15 | 1903 | 2 | 1A | 23 |
What a mess! What is the last observation about? How is GM missing a "first year" in one observation? GM and Ford are in the same sub-industry, but different industries? You'll have to keep track of what Profits and Profits_Ind mean. (And which industry level are profits at?)
The main issue is that this dataset conflates firm-year variables (profits in a given year) with firm-level variables (the first year of the firm. You can fix this by keeping three datasets, one firm-year dataset:
| Firm | Year | Profits |
|---|---|---|
| GM | 2000 | 5 |
| GM | 2001 | 5.5 |
| Ford | 2000 | -4 |
| Ford | 2001 | 7.5 |
| Ford | 2002 | 8 |
... and a firm-level dataset:
| Firm | First_year | IndustryDef | SubIndustryDef |
|---|---|---|---|
| GM | 1908 | 1 | 1A |
| Ford | 1903 | 1 | 1A |
... and an industry-year dataset:
| IndustryDef | Year | Profits |
|---|---|---|
| 1 | 2000 | 1 |
| 1 | 2001 | 13 |
| 1 | 2002 | 23 |
Now, the physical structure of each dataset communicates its logical structure: Every firm-year has a profit level, and each firm has a founding year. In fact, these databases are self-documenting! (Rule 6.C) Isn't that nice!?
Abstraction - use functions or classes
The last lecture already introduced two of the golden rules:
Writing your own functions is important for improving the clarity of your code because it
- separates different strands of logic (Rule 5.B)
- allows you to reuse code (Rule 5.A)
- prevents copy/paste errors (Rule 5.A)
The "Code and Data" reference has a short but very nice illustration justifying and explaining those rules. Do yourself a favor and read it!
I'll simply add that while a "wet jumpshot" is good in basketball, "wet code" is bad. You've Wasted Everyone's Time by Writing Everything Twice, which is bad even though We Enjoy Typing. Nah, you want your code to be DRY. It's very simple: Don't Repeat Yourself.
A few more points:
- Don't abstract for the sake of it! Writing functions can be a time-consuming waste of time that eats up time. (Lots of redundancy in that sentence was a waste of time to the reader, but at least it was short. Similarly, bad code is less problematic when it is short.)
- Rule 5.E: A magic number is a literal number embedded in your code. "Magic number" is a pejorative. Having numbers that act as in-line inputs and parameters can lead to errors and make modifying code very tough. For example, in a simple program, I wrote
2006and['AAPL','MSFT','VZ']several times throughout the code. This is bad practice! - Rule 5.D: If you are going to reuse your code, write a "unit test", which is a script that tests out the behavior of the function you've written to make sure it works as intended. It should run your function with a few different inputs, possibly inputs with deliberate errors, test the function's output against answer you know in advance are correct. Using "toy" or "small" datasets is essential to developing functions and code more broadly.
- Corollary: Don't unit test for the sake of it. You don't need to check what
round_a_number()does when you use a string as input.
- Corollary: Don't unit test for the sake of it. You don't need to check what
- On "classes": I don't personally use classes much, if at all. It wasn't necessary or extremely beneficial for my early projects (or so I, uniformed!, thought), so I didn't use them and learn them. Then inertia took over... But defining your own classes can be extremely useful! If you want to use them when warranted during this semester, absolutely go for it. I recommend reading the Whirlwind of Python section as a starter.
Documentation
This is maybe ok, but probably bad:
# Elasticity = Percent Change in Quantity / Percent Change in Price
# Elasticity = 0.4 / 0.2 = 2
# See Shapiro (2005), The Economics of Potato Chips,
# Harvard University Mimeo, Table 2A.
compute_welfare_loss(elasticity=2)The problem with comments is that if you change the code, you don't have to change the comments and the code will still run. E.g., if you change elasticity=2 above, you might easily forget to change the comment associated with it, or explain why.
So using comments makes it possible that your code becomes internally inconsistent! The next example prevents that, yet still documents the code just as well because it is self-documenting:
# See Shapiro (2005), The Economics of Potato Chips,
# Harvard University Mimeo, Table 2A.
percent_change_in_quantity = -0.4
percent_change_in_price = 0.2
elasticity = percent_change_in_quantity/percent_change_in_priceRelated points:
- Use the naming of variables and the structure of the code to help guide a reader through your operations
xandyare usually (but not always!) bad variable names because they are uninformative- The aim for self-documentation underlies the logic behind the "Good Data" section, the "Directory" rules, how we name files, ...
- Documentation is sometimes necessary and unavoidable. (Linking to "The Economics of Potato Chips" in the example above is excessive, the name suffices.)
- Documentation can clarify that, yes, I did mean to do this on purpose
With our remaining time today...
- Answer survey questions / additional practice
- GitHub Desktop tutorial?
- If needed, cover materials from last class we didn't have time for
- Try, ERROR, share:
- You have X minutes to create a sample python code with documentation, but purposely break a few golden rules in your code. Your code can be for any purpose you want: It can do tasks on lists and/or strings (a la last lecture), load a dataset and do a series of operations on the dataset, or anything you want!
- Share your code with your partner (probably fastest via email or switching computers) and try to identify the errors and bad habits in their code.
Credits
- This lecture leans heavily on the wonderful Code and Data for the Social Sciences: A Practitioner's Guide by Matthew Gentzkow and Jesse M. Shapiro1.
- The TA (Daniel Appierto) came up with "Try, error, share"