2.1. A case study in bad research¶
To illustrate the value of the golden rules, let’s pretend we are investigating an absolutely essential question: Are characters in Game of Thrones more likely to die when they head north or south?
2.1.1. One folder: A “common” data science project¶
So pretend I collected the text of the Game of Thrones books (currently 5, COME ON GEORGE). I also collected data on the names of characters so I can identify them in the text. I also collected data that maps the names of places to latitudes on the map. I have just about everything I need. I put these files in a folder, write some code to deal with data, and some code to produce output.
There were definitely intermediate steps, but I don’t remember exactly. Luckily, this project wasn’t “interactive, point-and-click in Excel” analysis. It was written in code! So it’s oooooobviously reproducible.
Let’s all look at the folder and try to figure it out? What do you think each file is, and how is the analysis conducted from data-to-draft?
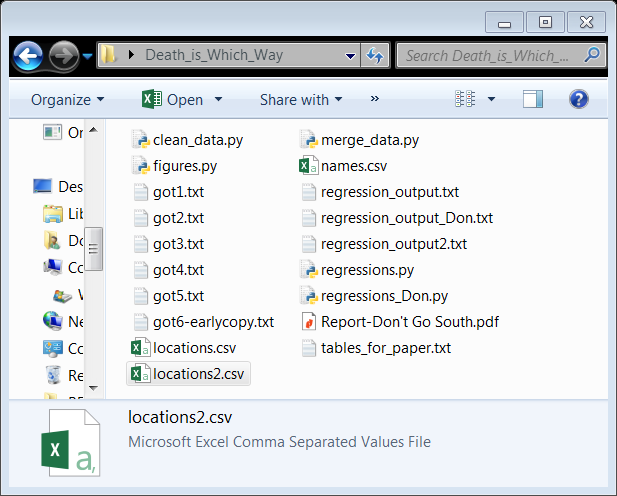
And no, this isn’t a joke - I’ve definitely seen “professional” researchers with projects organized like this in one way or another.
2.1.2. What are the possible issues with this?¶
Which data file(s) are the real input?
Do we run
clean_data.pyormerge_data.pyfirst to build the analysis sample?Do we run
figures.pyorregressions.pyfirst?Wait, maybe it’s actually
regressions_Don.pythat we should run!Clearly,
regression_output.txtcomes fromregressions.py(I hope!) andregression_output_Don.txtcomes fromregressions_Don.py…. But where on Earth didregression_output2.txtget conjured from?Speaking of mysteries, where the %^#! did
tables_for_paper.txtcome from? No python file mentions tables!Oh god, I just noticed two location files. I guess they are from different sources… but which is used by which files?
So, let’s see if we can’t improve this whole situation. Go to the next page!