6.2. Mechanics of running regressions¶
Note
These next few pages use a classic dataset called “diamonds” to introduce the regression methods. In lectures, we will use finance-oriented data.
6.2.1. Objectives¶
After this page,
You can fit a regression with
statsmodelsorsklearnthat includes dummy variables, categorical variables, and interaction terms.statsmodels: Nicer result tables, usually easier to specifying the regression modelsklearn: Easier to use within a prediction/ML exercise
With both modules: You can view the results visually
With both modules: You can get the coefficients, t-stats, R\(^2\), Adj R\(^2\), predicted values (\(\hat{y}\)), and residuals (\(\hat{u}\))
Let’s get our hands dirty quickly by loading some data.
# load some data to practice regressions
import seaborn as sns
import numpy as np
diamonds = sns.load_dataset('diamonds')
# this alteration is not strictly necessary to practice a regression
# but we use this in livecoding
diamonds2 = (diamonds.query('carat < 2.5') # censor/remove outliers
.assign(lprice = np.log(diamonds['price'])) # log transform price
.assign(lcarat = np.log(diamonds['carat'])) # log transform carats
.assign(ideal = diamonds['cut'] == 'Ideal')
# some regression packages want you to explicitly provide
# a variable for the constant
.assign(const = 1)
)
6.2.2. Our first regression with statsmodels¶
You’ll see these steps repeated a lot for the rest of the class:
Load the module
Load your data, and set up your y and X variables
Pick the model, usually something like:
model = <moduleEstimator>Fit the model and store the results, usually something like:
results = model.fit()Get predicted values, usually something like:
predicted = results.predict()
import statsmodels.api as sm # need this
y = diamonds2['lprice'] # pick y
X = diamonds2[['const','lcarat']] # set up all your X vars as a matrix
# NOTICE I EXPLICITLY GIVE X A CONSTANT SO IT FITS AN INTERCEPT
model1 = sm.OLS(y,X) # pick model type (OLS here) and specify model features
results1 = model1.fit() # estimate / fit
print(results1.summary()) # view results (coefs, t-stats, p-vals, R2, Adj R2)
y_predicted1 = results1.predict() # get the predicted results
residuals1 = results1.resid # get the residuals
#residuals1 = y - y_predicted1 # another way to get the residuals
print('\n\nParams:')
print(results1.params) # if you need to access the coefficients (e.g. to save them), results.params
OLS Regression Results
==============================================================================
Dep. Variable: lprice R-squared: 0.933
Model: OLS Adj. R-squared: 0.933
Method: Least Squares F-statistic: 7.542e+05
Date: Wed, 24 Mar 2021 Prob (F-statistic): 0.00
Time: 22:06:38 Log-Likelihood: -4073.2
No. Observations: 53797 AIC: 8150.
Df Residuals: 53795 BIC: 8168.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 8.4525 0.001 6193.432 0.000 8.450 8.455
lcarat 1.6819 0.002 868.465 0.000 1.678 1.686
==============================================================================
Omnibus: 775.052 Durbin-Watson: 1.211
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1334.265
Skew: 0.106 Prob(JB): 1.85e-290
Kurtosis: 3.742 Cond. No. 2.10
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Params:
const 8.452512
lcarat 1.681936
dtype: float64
6.2.3. A better way to regress with statsmodels¶
Tip
This is my preferred way to run a regression in Python unless I have to use sklearn.
In the above, replace
y = diamonds2['lprice'] # pick y
X = diamonds2[['const','lcarat']] # set up all your X vars as a matrix
model1 = sm.OLS(y,X) # pick model type (OLS here) and specify model features
with this
model1 = sm.OLS.from_formula('lprice ~ lcarat',data=diamonds2)
which I can replace with this (after adding from statsmodels.formula.api import ols as sm_ols to my imports)
model1 = sm_ols('lprice ~ lcarat',data=diamonds2)
WOW! This isn’t just more convenient (1 line is less than 3), I like this because
You can set up the model (the equation) more naturally. Simply tell it the name of your dataframe and then you can regress height on weight (\(weight=a+b*height\)) by writing `weight ~ height’.
You don’t need to include the constant
aor the coefficientbYou don’t need to set up the y and X variables as explicit objects
You can add more variables to the regression just as easily. To estimate \(y=a+b*X+c*Z\), write this inside the function:
y ~ X + ZIt allows you to EASILY include categorical variables (see below)
It allows you to EASILY include interaction effects (see below)
from statsmodels.formula.api import ols as sm_ols # need this
model2 = sm_ols('lprice ~ lcarat', # specify model (you don't need to include the constant!)
data=diamonds2)
results2 = model2.fit() # estimate / fit
print(results2.summary()) # view results ... identical to before
y_predicted2 = results2.predict() # get the predicted results
residuals2 = results2.resid # get the residuals
#residuals1 = y - y_predicted1 # another way to get the residuals
print('\n\nParams:')
print(results2.params) # if you need to access the coefficients (e.g. to save them), results.params
OLS Regression Results
==============================================================================
Dep. Variable: lprice R-squared: 0.933
Model: OLS Adj. R-squared: 0.933
Method: Least Squares F-statistic: 7.542e+05
Date: Wed, 24 Mar 2021 Prob (F-statistic): 0.00
Time: 22:06:38 Log-Likelihood: -4073.2
No. Observations: 53797 AIC: 8150.
Df Residuals: 53795 BIC: 8168.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 8.4525 0.001 6193.432 0.000 8.450 8.455
lcarat 1.6819 0.002 868.465 0.000 1.678 1.686
==============================================================================
Omnibus: 775.052 Durbin-Watson: 1.211
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1334.265
Skew: 0.106 Prob(JB): 1.85e-290
Kurtosis: 3.742 Cond. No. 2.10
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Params:
Intercept 8.452512
lcarat 1.681936
dtype: float64
Note
We will cover what all these numbers mean later, but this page is focusing on the how-to.
6.2.4. Regression with sklearn¶
sklearn is pretty similar but
when setting up the model object, you don’t tell it what data to put into the model
you call the model object, and then fit it on data, with
model.fit(X,y)it doesn’t have the nice summary tables
from sklearn.linear_model import LinearRegression
y = diamonds2['lprice'] # pick y
X = diamonds2[['const','lcarat']] # set up all your X vars as a matrix
# NOTICE I EXPLICITLY GIVE X A CONSTANT SO IT FITS AN INTERCEPT
model3 = LinearRegression() # set up the model object (but don't tell sklearn what data it gets!)
results3 = model3.fit(X,y) # fit it, and tell it what data to fit on
print('INTERCEPT:', results3.intercept_) # to get the coefficients, you print out the intercept
print('COEFS:', results3.coef_) # and the other coefficients separately (yuck)
y_predicted3 = results3.predict(X) # get predicted y values
residuals3 = y - y_predicted3 # get residuals
INTERCEPT: 8.452511832951718
COEFS: [0. 1.68193567]
That’s so much uglier. Why use sklearn?
Because sklearn is the go-to for training models using more sophisticated ML ideas (which we will talk about some later in the course!). Two nice walkthroughs:
This guide from the PythonDataScienceHandbook (you can use different data though)
The “Linear Regression” section here shows how you can run regressions on training samples and test them out of sample
6.2.5. Plotting the regression fit¶
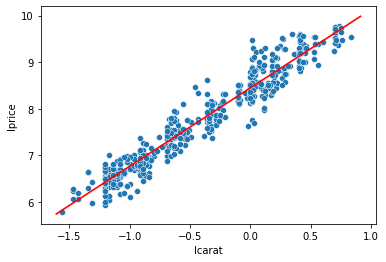
Once you save the predicted values (\(\hat{y}\)), it’s easy to add it to a plot:
import matplotlib.pyplot as plt
# step 1: plot our data as you want
sns.scatterplot(x='lcarat',y='lprice',
data=diamonds2.sample(500,random_state=20)) # sampled just to avoid overplotting
# step 2: add the fitted regression line (the real X values and the predicted y values)
sns.lineplot(x=diamonds2['lcarat'],y=y_predicted1,color='red')
plt.show()
Note
sns.lmplot and sns.regplot will put a regression line on a scatterplot without having to set up and run a regression, but they also overplot the points when you have a lot of data. That’s why I used the approach above - scatterplot a subsample of the data and then overlay the regression line.
One other alternative is to use sns.lmplot and sns.regplot, but use the x_bins parameter to report a “binned scatterplot”. Check it out if you’re curious.
6.2.6. Including dummy variables¶
Suppose you started by estimating the price of diamonds as a function of carats
but you realize it will be different for ideal cut diamonds. That is, a 1 carat diamond might cost $1,000, but if it’s ideal, it’s an extra $500 dollars.
Notice that \(\beta_0\) in this model are the same for ideal and non-ideal.
Tip
Here is how you run this test: You just add the dummy variable as a new variable in the formula!
# ideal is a dummy variable = 1 if ideal and 0 if not ideal
print(sm_ols('lprice ~ lcarat + ideal', data=diamonds2).fit().summary())
OLS Regression Results
==============================================================================
Dep. Variable: lprice R-squared: 0.936
Model: OLS Adj. R-squared: 0.936
Method: Least Squares F-statistic: 3.914e+05
Date: Wed, 24 Mar 2021 Prob (F-statistic): 0.00
Time: 22:06:44 Log-Likelihood: -3136.4
No. Observations: 53797 AIC: 6279.
Df Residuals: 53794 BIC: 6306.
Df Model: 2
Covariance Type: nonrobust
=================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------
Intercept 8.4182 0.002 5415.779 0.000 8.415 8.421
ideal[T.True] 0.1000 0.002 43.662 0.000 0.096 0.105
lcarat 1.6963 0.002 878.286 0.000 1.692 1.700
==============================================================================
Omnibus: 794.680 Durbin-Watson: 1.241
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1394.941
Skew: 0.101 Prob(JB): 1.24e-303
Kurtosis: 3.763 Cond. No. 2.67
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.

6.2.7. Including categorical variables¶
Dummy variables take on two values (on/off, True/False, 0/1). Categorical variables can take on many levels. “Industry” and “State” are typical categorical variables in finance applications.
sm_ols also processes categorical variables easily!
Tip
Here is how you run this test: You just add the categorical variable as a new variable in the formula!
Warning
WARNING 1: A good idea is to ALWAYS put your categorical variable inside of “C()” like below. This tells statsmodels that the variable should be treated as a categorical variable EVEN IF it is a number. (Which would otherwise be treated like a number.)
Warning
WARNING 2: You don’t create a dummy variable for all the categories! As long as you include a constant in the regression (\(a\)), one of the categories is covered by the constant. Above, “ideal” is captured by the intercept.
And if you look at the results of the next regression, the “ideal” cut level doesn’t have a coefficient. Statsmodels automatically drops one of the categories when you use the formula approach. Nice!!!
But if you manually set up the regression in statsmodels or sklearn, you have to drop one level yourself!!!
print(sm_ols('lprice ~ lcarat + C(cut)', data=diamonds2).fit().summary())
OLS Regression Results
==============================================================================
Dep. Variable: lprice R-squared: 0.937
Model: OLS Adj. R-squared: 0.937
Method: Least Squares F-statistic: 1.613e+05
Date: Wed, 24 Mar 2021 Prob (F-statistic): 0.00
Time: 22:06:44 Log-Likelihood: -2389.9
No. Observations: 53797 AIC: 4792.
Df Residuals: 53791 BIC: 4845.
Df Model: 5
Covariance Type: nonrobust
=======================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------
Intercept 8.5209 0.002 4281.488 0.000 8.517 8.525
C(cut)[T.Premium] -0.0790 0.003 -28.249 0.000 -0.084 -0.074
C(cut)[T.Very Good] -0.0770 0.003 -26.656 0.000 -0.083 -0.071
C(cut)[T.Good] -0.1543 0.004 -38.311 0.000 -0.162 -0.146
C(cut)[T.Fair] -0.3111 0.007 -46.838 0.000 -0.324 -0.298
lcarat 1.7014 0.002 889.548 0.000 1.698 1.705
==============================================================================
Omnibus: 792.280 Durbin-Watson: 1.261
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1178.654
Skew: 0.168 Prob(JB): 1.14e-256
Kurtosis: 3.643 Cond. No. 7.20
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.

6.2.8. Including interaction terms¶
Suppose that an ideal cut diamond doesn’t just add a fixed dollar value to the diamond. Perhaps it also changes the value of having a larger diamond. You might say that
A high-quality cut is even more valuable for a larger diamond than it is for a small diamond. (“A great cut makes a diamond sparkle, but it’s hard to see sparkle on a tiny diamond no matter what.”)
In other words, the effect of carats depends on the cut and vice versa
In other words, “the cut variable interacts with the carat variable”
So you might say that, “a better cut changes the slope/coefficient of carat”
Or equivalently, “a better cut changes the return on a larger carat”
Graphically, it’s easy to see, as sns.lmplot by default gives each cut a unique slope on carats:
import matplotlib.pyplot as plt
# add reg lines to plot
fig, ax = plt.subplots()
ax = sns.regplot(data=diamonds2.query('cut == "Fair"'),
y='lprice',x='lcarat',scatter=False,ci=None)
ax = sns.regplot(data=diamonds2.query('cut == "Ideal"'),
y='lprice',x='lcarat',scatter=False,ci=None)
# scatter
sns.scatterplot(data=diamonds2.groupby('cut').sample(80,random_state=99).query('cut in ["Ideal","Fair"]'),
x='lcarat',y='lprice',hue='ideal',ax=ax)
plt.show()
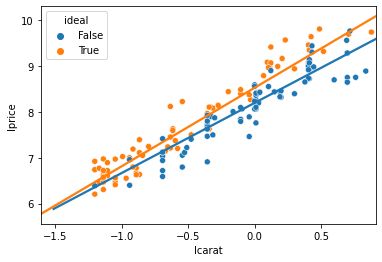
Those two different lines above are estimated by
If you plug in 1 for \(ideal\), you get the line for ideal diamonds as
If you plug in 0 for \(ideal\), you get the line for fair diamonds as
So, by including that interaction term, you get that the slope on carats is different for Ideal than Fair diamonds.
Tip
Here is how you run this test: You just add the two variables as a new variable in the formula, along with one term where they are both multiplied!
# you can include the interaction of x and z by adding "+x*z" in the spec, like:
sm_ols('lprice ~ lcarat + ideal + lcarat*ideal', data=diamonds2.query('cut in ["Fair","Ideal"]')).fit().summary()
| Dep. Variable: | lprice | R-squared: | 0.930 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.930 |
| Method: | Least Squares | F-statistic: | 1.022e+05 |
| Date: | Wed, 24 Mar 2021 | Prob (F-statistic): | 0.00 |
| Time: | 22:06:44 | Log-Likelihood: | -1650.8 |
| No. Observations: | 23106 | AIC: | 3310. |
| Df Residuals: | 23102 | BIC: | 3342. |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 8.1954 | 0.007 | 1232.871 | 0.000 | 8.182 | 8.208 |
| ideal[T.True] | 0.3302 | 0.007 | 46.677 | 0.000 | 0.316 | 0.344 |
| lcarat | 1.5282 | 0.015 | 103.832 | 0.000 | 1.499 | 1.557 |
| lcarat:ideal[T.True] | 0.1822 | 0.015 | 12.101 | 0.000 | 0.153 | 0.212 |
| Omnibus: | 117.253 | Durbin-Watson: | 1.231 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 145.473 |
| Skew: | 0.097 | Prob(JB): | 2.58e-32 |
| Kurtosis: | 3.337 | Cond. No. | 19.6 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
This shows that a 1% increase in carats is associated with a 1.52% increase in price for fair diamonds, but a 1.71% increase for ideal diamonds (1.52+0.18).
Thus: The return on carats is different (and higher) for better cut diamonds!