5.2.1. Basics and Notation¶
Regression is the single most important tool at the econometrician’s disposal
Regression analysis is concerned with the description and evaluation of the relationship between a variable typically called the dependent variable, and one or more other variables, typically called the independent or explanatory variables.
Alternative vocabulary:
y |
x |
|---|---|
dependent variable |
independent variables |
regressand |
regressors |
effect variable |
causal variables |
explained variable |
explanatory variables |
features |
5.2.1.1. The regression “model” and terminology¶
Suppose you want to describe the relationship between two variables, y and X. You might model that relationship as a straight line:
But that line can’t exactly fit all the points of data, so you need to account for the discrepancies, and so we add a “error term” or “disturbance” denoted by \(u\)
Now, we want to estimate \(a\) and \(\beta\) to best “fit” the data. Imagine you pick/estimate \(\hat{a}\) and \(\hat{\beta}\) to fit the data. If you apply that to all the X data points like \(\hat{a} + \hat{\beta}x\) , then you get a predicted value for \(y\):
We call \(\hat{y}\) the “fitted values” or the “predicted values” of y. And the difference between each actual \(y\) and the predicted \(\hat{y}\) is called the residual or error:
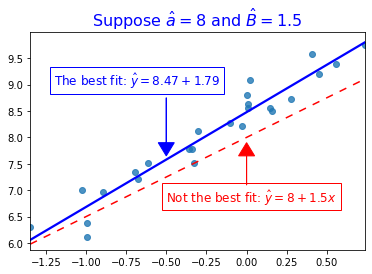
You can see all this visually in this graph, where I’ve plotted some X and y variable, and decided to see how well a line with \(\hat{\alpha}=8\) and \(\hat{\beta}=1.5\) fit it:
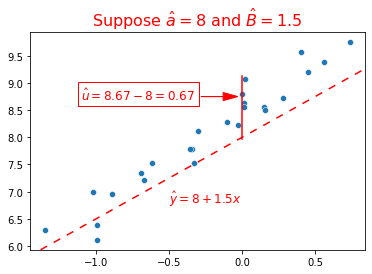
So after you pick an \(\hat{a}\) and \(\hat{\beta}\), you compute the vertical distance between the fitted line and every point.
The goal of estimation (any estimation, including regression) is to make these errors as “small” as possible. Regression is aka’ed as “Ordinary Least Squares” which as it sounds, takes those errors, squares them, adds those up, and minimizes the sum
and we can substitute \(\hat{y}\) in to that and get:
By solving this problem, you’re in essence “plotting” a bunch of these lines (with corresponding slopes and intercepts), and each time, you get the error for each datapoint (\(\hat{u}\)), and choosing the line that fits the data the best.
So, to combine this with the “Modeling process” page, regression follows the same steps as any estimation:
Select a model. In a regression, the model is a line (if you only have 1 X variable) or a hyperplane (if you have many X variables).
Select a loss function. In a regression, it’s the sum of squared errors.
Minimize the loss. You can solve the minimum analytically (take the derivative, …) or numerically (gradient descent). But good news: The python packages we use handle this for you.
Here, the actual regression line is different than what I plotted above, and your eyes probably agree that the blue line fits it quite well!