2.5. Applying the golden rules to our bda project folder¶
Let’s apply those rules to our cursed analysis of character death in Game of Thrones and see if this makes the project easier to replicate (in terms of accuracy and time required).
(Note, there are other ways to efficiently divide up analysis than what I propose here that have merit! Do not take this exact scheme as “gospel”.)
2.5.1. Folders separated by function - part 1¶
I’ve split the project into two sub-directories: “build” (whose function is to build the sample from the raw data inputs) and “analysis”. These are two-sub tasks of any data project, and here, I’ve chosen to treat them as different functions and thus they get different folders (Rule 3.A).
2.5.2. Folders separated by function - part 2¶
The build folder takes “inputs”, which are processed by files inside “code”, and places the analysis sample (now explicitly created!) in “output”. Notice the inputs and outputs are clearly separated! (Rule 3.B) Temp files are created along the way, but are not “output”.
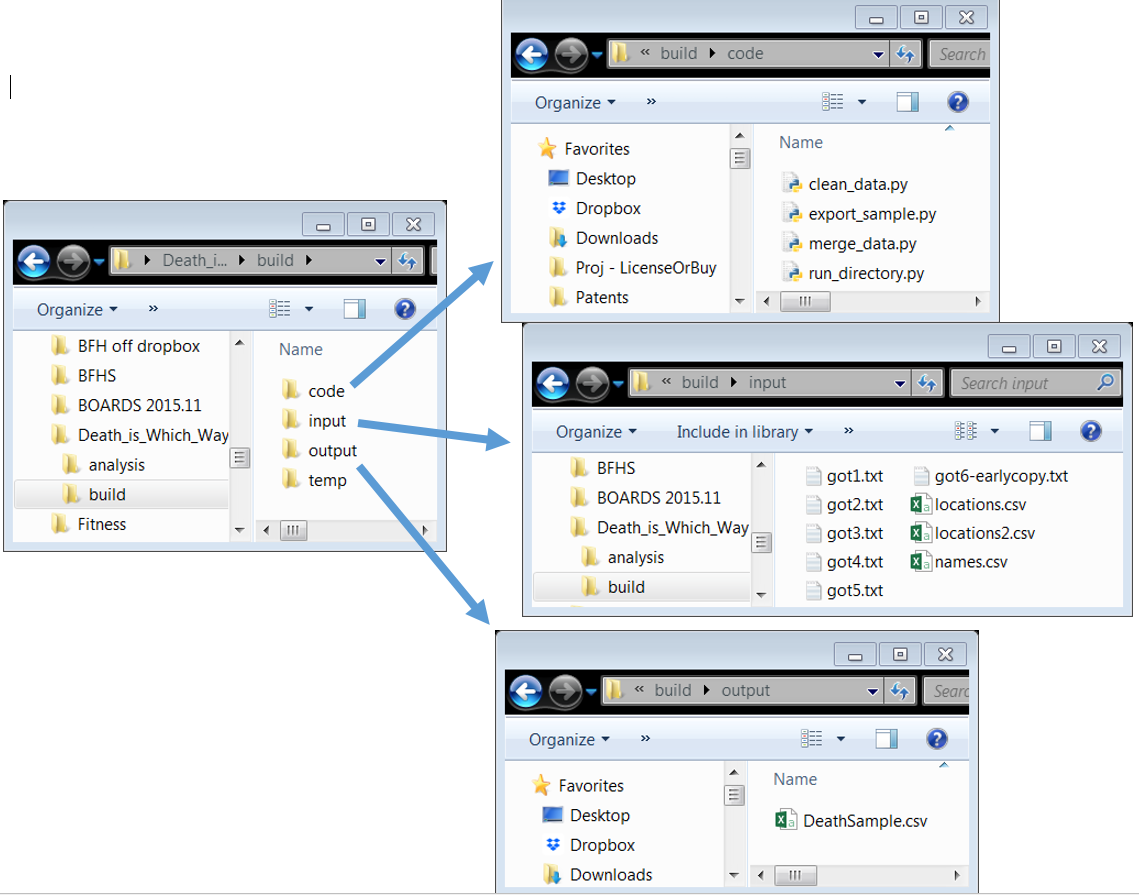
Also, notice the new file run_directory.py. It very quickly and plainly documents how to run the entire code in the “build” project (Rule 1.B), and makes it easy to do so every time (Rule 2.B) before you push it back to the master repo on GitHub (Rule 2.A). run_directory.py is so simple, it is self-documenting (Rule 6.C).
# to create DataSample.csv:
clean_slate() # deletes all temp files and all output files
execfile(clean_data.py)
execfile(merge_data.py)
execfile(export_data.py)