3.3.5. Better Plots¶
3.3.5.1. The theory of good visuals¶
There is an enormous amount of scholarship and debate about what makes for effective graphs and I can’t possibly do the field justice. Below is simply one person’s distillation of some tips that are reasonably well agreed upon. I’m aiming for concise here so that we can practice, but if you want more, visit the links below.
pie charts: humans stink at interpreting angles
stacked bar charts: tough to decode trends
make your reader do math: if \(x-y\) is interesting, don’t plot \(x\) and \(y\) separately, just plot \(x-y\)
misleading scales
3D unless absolutely necessary (and it almost surely isn’t)
distracting chart junk
unnecessary colors
spaghetti charts: too many lines
Show the data, reduce the clutter, and integrate the text and the graph
graphs should aspire to be sufficient to understand without reading the text
Control the aspect ratio
Think about whether you need to include zero. Sometimes excluding it makes the figure misleading. Sometimes including it (and expanding the y-axis to do so) hides the variation you’re describing.
Facilitate comparisons:
by placing figure components next to or above (depends!) the stuff it is compared to
by using the same axis (two y-axes is usually bad!)
labels > legends! (so readers eyes don’t have to dart back and forth)
sort in meaningful orders (i.e. not alphabetically!)
3.3.5.2. Transforming bad figures to good ones¶

Look at the before/after examples here. This article is also wonderful for understanding the “why”s of good data viz
3.3.5.3. Customizing figure aspects¶
Create your plot in pandas or seaborn
Format the figure as much as possible from within the pandas or seaborn function. I have some info on that below.
If/when necessary, use
matplotlibto customize the figure.
After you create a figure object, subsequent calls to that object will modify it
Copy this code below into a python file and run it. Then uncomment out the next line, and rerun. See the change it made. Then uncomment the next line, rerun, and so on.
### THIS IS A SILLY ILLUSTRATION! LOOK AT THE DROP DOWNS BELOW, AND
### THE EXAMPLES THROUGHOUT, FOR MORE REALISTIC SET UPS FOR HOW
### WE MODIFY PLOTS FROM PANDAS/SEABORN FUNCTIONS
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2, 100)
plt.plot(x, x, label='linear') # creates plt obj
# plt.plot(x, x**2, label='quadratic') # adds another plot on top
# plt.plot(x, x**3, label='cubic') # again
# plt.xlabel('x label')
# plt.ylabel('y label')
# plt.title("Simple Plot")
# plt.legend()
# plt.show()
[<matplotlib.lines.Line2D at 0x1f147d3f670>]

Warning
That example above is just to illustrate how we modify figure objects. In practice, I doubt you will ever plot with the plt.plot() function.
Since, you’ll use pandas and seaborn, when you modify figure objects, you’ll usually be modifying objects you name fig or ax (or similar, like f1, f2, etc…)
Formatting plots in pandas
Optional: Set up the size of your overall figure and create
figandaxobjects so you can manipulate the figures:fig, ax = plt.subplots(figsize=(width in inches,height)).Advanced use: If you are manually creating subfigures, use
fig, ax = plt.subplots(#,#,figsize=(width in inches,height))to tell it how many rows and columns of subfigures to set up.
ax = <plot commands>, e.g.ax = df.plot()The pandas plot function can set your title and change many elements as arguments. See the documentation.
Ex:
ax = df.plot(title="My Title")
Modify the figure by accessing the
figandaxcommands as needed.
Remember, there are many ways to customize plots! Here is one set of steps you might use:
fig, ax = plt.subplots(figsize=(<width>,<height>))
ax = <df.plot()>
ax.<customizations>
fig.<customizations>
Formatting plots in seaborn
Optional: Set up the size of your overall figure and create
figandaxobjects so you can manipulate the figures:fig, ax = plt.subplots(figsize=(width in inches,height)).Advanced use: If you are manually creating subfigures, use
fig, ax = plt.subplots(#,#,figsize=(width in inches,height))to tell it how many rows and columns of subfigures to set up.
ax = <plot commands>, e.g.ax = sns.lineplot(data=df,x='x',y='y')Alt: Assign the plot to ax within the function, e.g.
sns.lineplot(data=df,x='x',y='y',ax=ax)
You can frequently modify
snsplots with a method chain, e.g.sns.lineplot(data=df,x='x',y='y').set(title="My Title",xlabel="X")Modify the figure by accessing the
figandaxcommands as needed.
Remember, there are many ways to customize plots! Here is one set of steps you might use:
fig, ax = plt.subplots(figsize=(<width>,<height>))
ax = <sns.function()>
ax.<customizations>
fig.<customizations>
For changes outside the pd and sns plot functions: Honestly, I can’t do much better than this page.
3.3.5.4. Practice: Fixer Upper¶
Let’s say I want to plot the average leverage for firms in different industries before and after the 2008 financial crisis, and I wanted to see how it evolved for HIGH LEVERAGE industries vs. LOW LEVERAGE industries.
The code (hidden) below spits out the raw content.
#!pip install plotly
%matplotlib inline
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px # pip install plotly.. the animation below is from plotly module
from io import BytesIO
from zipfile import ZipFile
from urllib.request import urlopen
url = 'https://github.com/LeDataSciFi/ledatascifi-2021/blob/main/data/CCM_cleaned_for_class.zip?raw=true'
#firms = pd.read_stata(url) <-- would work, but GH said "too big" and forced me to zip it,
# so here is the work around to download it:
with urlopen(url) as request:
data = BytesIO(request.read())
with ZipFile(data) as archive:
with archive.open(archive.namelist()[0]) as stata:
ccm = pd.read_stata(stata)
# get industry-avg leverage (for each year)
# I use 2 digit SIC codes here to define an industry
ccm['sic3'] = pd.to_numeric(ccm['sic3'], errors='coerce')
sic2_year = (ccm
.assign(sic2 = ccm['sic3']//10)
.query('fyear >= 2003 & fyear <= 2013 & sic2 != 99 & sic2 != 41')
.groupby(['sic2','fyear'])
[['td_a','prof_a']].mean()
)
# reduce to hi/lo lev industrys
lo4 = sic2_year.query('fyear == 2007')['td_a'].sort_values().reset_index()['sic2'][:4].to_list()
hi4 = sic2_year.query('fyear == 2007')['td_a'].sort_values().reset_index()['sic2'][-4:].to_list()
inds_to_examine = lo4.copy()
inds_to_examine.extend(hi4)
# add industry labels to dataset
sic2_labels = pd.DataFrame({
'sic2': [82.0, 31.0, 63.0, 47.0, 70.0, 27.0, 75.0, 61.0],
'sic2_ind': ['Educational Services','Leather Products','Insurance Carriers','Transportation Services',
'Hotels','Printing & Publishing','Auto Repairs','Nondepository Institutions']})
sic2_year = sic2_year.reset_index().merge(sic2_labels,on='sic2')
# add hi/lo industry leverage variable
sic2_year['Group'] = 'High Lev Industries'
sic2_year.loc[ sic2_year['sic2'].isin(lo4), 'Group'] = 'Low Lev Industries'
ax = sns.lineplot(data = sic2_year, x = 'fyear', y='prof_a', hue='sic2')
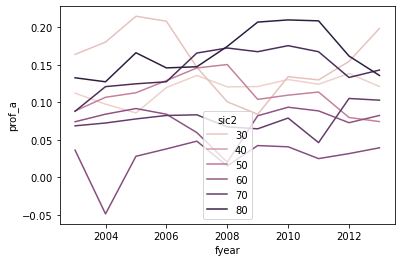
BUT WOW IS THIS UGLY AND ALMOST USELESS
Which series is which industry? (color scales mean nothing here)
Which series are the high leverage industries? Which are low?
Bad axis titles
The legend is on top of the data
OMG: The legend is showing the wrong industry numbers (it should be include 47, 31, 82, …)

Let’s take a first pass at cleaning this up:
The lineplot documentation doesn’t allow for facets with the
colparameter, but the bottom of the documentation saysrelplotcan facet lineplotsSo
relplot+kind="line"= same graphAnd
relplot+kind="line"+col='Group'adds facets for high/low lev industriesremove the legend, we will add text labels later
Set the title, facet titles, axis titles (a little trickier because of the facts)
# I call this "g" to follow convention in sns documentation
# "g" is the whole facet "g"rid object relplot creates
g = sns.relplot(data = sic2_year, x = 'fyear', y='prof_a',
hue='sic2', kind='line', col='Group',
legend=False)
g.fig.suptitle('Profitability by Industry', fontsize=15, )
g.fig.subplots_adjust(top=0.85) # Reduce plot to make room
g.set_axis_labels("Year", "Profitability")
g.axes[0][0].set_title('High Lev Industries')
g.axes[0][1].set_title('Low Lev Industries')
print()
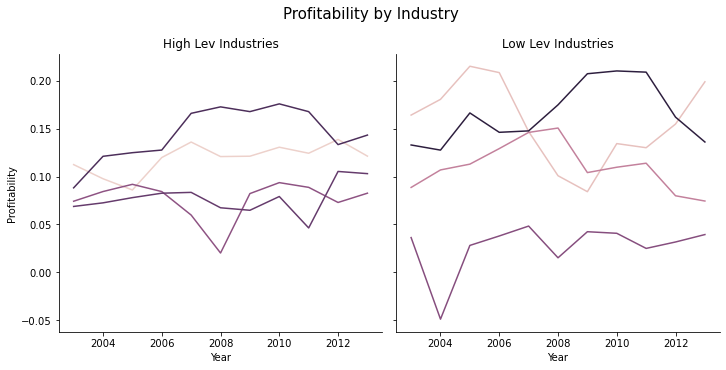
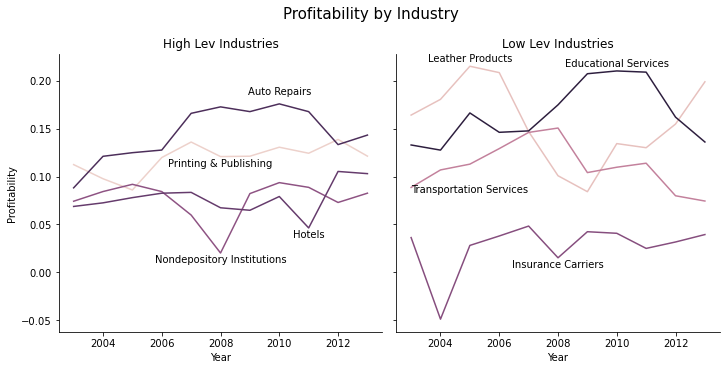
Now we just need to add labels so we know what lines are which industries. This is a little messy.
# remake the graph
g = sns.relplot(data = sic2_year, x = 'fyear', y='prof_a',
hue='sic2', kind='line', col='Group',
legend=False)
g.fig.suptitle('Profitability by Industry', fontsize=15, )
g.fig.subplots_adjust(top=0.85) # Reduce plot to make room
g.set_axis_labels("Year", "Profitability")
g.axes[0][0].set_title('High Lev Industries')
g.axes[0][1].set_title('Low Lev Industries')
# now set up the labels to replace the legend - I'm going for "excellent"
# I'll put the labels on these data points
ind_year_for_labels = '(fyear == 2008 & sic2 == 61) | (fyear == 2011 & sic2 == 70) | (fyear == 2010 & sic2 == 75) |' + \
'(fyear == 2008 & sic2 == 27) | (fyear == 2010 & sic2 == 82) | (fyear == 2005 & sic2 == 31) |' + \
'(fyear == 2008 & sic2 == 63) | (fyear == 2005 & sic2 == 47)'
# and each one will be higher or lower than it's data point by
# some amount so that text doesnt cover the lines
sic2_year['y_offset'] = -.01
sic2_year.loc[ sic2_year['sic2'] == 75, 'y_offset'] = .01 # autorepairs
sic2_year.loc[ sic2_year['sic2'] == 47, 'y_offset'] = -.03 # trans
sic2_year.loc[ sic2_year['sic2'] == 31, 'y_offset'] = .005 # leather
sic2_year.loc[ sic2_year['sic2'] == 82, 'y_offset'] = .005 # edu
# this funct will add the text to a subfigure
def label_point(df, x, y, val, ax, y_offset):
for i, point in df.iterrows():
ax.text(point[x], point[y]+point[y_offset], str(point[val]),horizontalalignment='center')
# add the labels to the graph
high_sub = sic2_year.query('Group == "High Lev Industries" & ('+ind_year_for_labels+')')
label_point(high_sub,'fyear','prof_a','sic2_ind', g.axes[0][0],'y_offset')
high_sub = sic2_year.query('Group == "Low Lev Industries" & ('+ind_year_for_labels+')')
label_point(high_sub,'fyear','prof_a','sic2_ind', g.axes[0][1],'y_offset')
3.3.5.5. Practice: Thinking and planning¶
Questions:
Suppose we create a scatter plot but find that due to the large number of points it’s hard to interpret. What are two things we can do to fix this issue?
Suppose that we create an n-by-n FacetGrid. How big can “n” get?
What are the two things about faceting which make it appealing?
When is
sns.pairplotmost useful?
Answers
Q1
One way to fix this issue would be to sample the points. Another way to fix it would be to use a hex plot.
Q2
A matter of size and visibility, but 5x5 is probably as large as you want to go.
Q3
It’s a easy way to show info about additional variables of interest to a figure.
Q4
Especially useful when you’re exploring the dataset.
3.3.5.6. Interactive plots: plotly¶
I want to show you how far we can push this exploration of leverage and firm value. The code uses plotly’s subpackage plotly-express which is ridiculously easy to use, for how cool these plots are.
And as an exercise, you might critique these - I certainly think there are aspects to improve!
#!pip install plotly
%matplotlib inline
import pandas as pd
import numpy as np
import plotly.express as px # pip install plotly.. the animation below is from plotly module
from io import BytesIO
from zipfile import ZipFile
from urllib.request import urlopen
url = 'https://github.com/LeDataSciFi/ledatascifi-2021/blob/main/data/CCM_cleaned_for_class.zip?raw=true'
#firms = pd.read_stata(url) <-- would work, but GH said "too big" and forced me to zip it,
# so here is the work around to download it:
with urlopen(url) as request:
data = BytesIO(request.read())
with ZipFile(data) as archive:
with archive.open(archive.namelist()[0]) as stata:
firms = pd.read_stata(stata)
# firms = pd.read_stata('https://github.com/LeDataSciFi/ledatascifi-2021/blob/main/data/CCM_cleaned_for_class.zip?raw=true')
firms.name = "Firms"
# https://jupyterbook.org/guide/05_faq.html#How-can-I-include-interactive-Plotly-figures?
# the lines before and after the fig help make sure this is viewable on the website
# but shouldn't be necessary just for notebook viewing... but I'm not sure about github viewing
from IPython.core.display import display, HTML
from plotly.offline import init_notebook_mode, plot
init_notebook_mode(connected=True)
fig = (
firms
.query('(fyear < 2014) & (mb < 5) & (td_a >= 0) & (td_a < 1.5) ') # some sensible limits
.groupby(['state','gsector','fyear'])
.agg({'td_a':'mean','mb':'mean','at':'sum','lpermno':'count'
}) # we need the # of firms per industry-state for an extra filter
# and I wanted the total assets summed so bigger industries get bigger circles
.rename(columns={'td_a':'Avg Book Leverage', 'mb':'Avg Market to Book','lpermno':'Num_Firms'})
.query('Num_Firms > 20 ') # disgard small industry-states
.reset_index() # get fyear as a variable for plotting function
.pipe(
(px.scatter,'data_frame'),
y='Avg Market to Book', x='Avg Book Leverage', animation_frame="fyear",
range_x=[0,.5], range_y=[0,2], hover_data=["state","gsector"],
title = "State-By-Industry Avg Leverage and Avg Firm Value"
)
)
plot(fig, filename = 'ind-state mb vs lev.html')
display(HTML('ind-state mb vs lev.html'))
fig = (
firms
.query('(fyear < 2014) & (mb < 5) & (td_a >= 0) & (td_a < 1.5) ') # some sensible limits
.query('state in ["CA","NY"] & gsector in ["40","45"]') # sample restriction
.rename(columns={'td_a':'Book Leverage'})
.reset_index() # get fyear as a variable for plotting function
.pipe(
(px.scatter,'data_frame'),
y='mb',x='Book Leverage',animation_frame="fyear",
range_x=[0,1.5], range_y=[0,5],
facet_row="gsector", facet_col="state",
hover_data=["state","gsector"],
title = "Leverage and Firm Value"
)
)
plot(fig, filename = 'mb vs lev for each state-ind.html')
display(HTML('mb vs lev for each state-ind.html'))
One more: This is a replication of a famous Hans Rosling TED talk figure using the well-known gapminder data:
fig = px.scatter(px.data.gapminder(), x="gdpPercap", y="lifeExp",
size="pop", color="continent",animation_frame="year",
range_y=[30,85],
hover_name="country", log_x=True, size_max=60)
plot(fig, filename = 'hans.html')
display(HTML('hans.html'))