{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Common tasks\n",
"\n",
"```{important}\n",
"\n",
"Yes, this page is kind of long. But that's because it has a lot of useful info!\n",
"\n",
"Use the page's table of contents to the right to jump to what you're looking for. \n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Reshaping data\n",
"\n",
"In the [shape of data](02b_pandasVocab) page, I explained the concept of wide vs. tall data with this example: "
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Tall:\n"
]
},
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Firm | \n",
" Year | \n",
" Sales | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ford | \n",
" 2000 | \n",
" 10 | \n",
"
\n",
" \n",
" | 1 | \n",
" Ford | \n",
" 2001 | \n",
" 12 | \n",
"
\n",
" \n",
" | 2 | \n",
" Ford | \n",
" 2002 | \n",
" 14 | \n",
"
\n",
" \n",
" | 3 | \n",
" Ford | \n",
" 2003 | \n",
" 16 | \n",
"
\n",
" \n",
" | 4 | \n",
" GM | \n",
" 2000 | \n",
" 11 | \n",
"
\n",
" \n",
" | 5 | \n",
" GM | \n",
" 2001 | \n",
" 13 | \n",
"
\n",
" \n",
" | 6 | \n",
" GM | \n",
" 2002 | \n",
" 13 | \n",
"
\n",
" \n",
" | 7 | \n",
" GM | \n",
" 2003 | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Sales | \n",
"
\n",
" \n",
" | Firm | \n",
" Ford | \n",
" GM | \n",
"
\n",
" \n",
" | Year | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2000 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
" | 2001 | \n",
" 12 | \n",
" 13 | \n",
"
\n",
" \n",
" | 2002 | \n",
" 14 | \n",
" 13 | \n",
"
\n",
" \n",
" | 2003 | \n",
" 16 | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Sales | \n",
"
\n",
" \n",
" | Year | \n",
" 2000 | \n",
" 2001 | \n",
" 2002 | \n",
" 2003 | \n",
"
\n",
" \n",
" | Firm | \n",
" | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ford | \n",
" 10 | \n",
" 12 | \n",
" 14 | \n",
" 16 | \n",
"
\n",
" \n",
" | GM | \n",
" 11 | \n",
" 13 | \n",
" 13 | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" Sales | \n",
"
\n",
" \n",
" | Year | \n",
" Firm | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2000 | \n",
" Ford | \n",
" 10 | \n",
"
\n",
" \n",
" | GM | \n",
" 11 | \n",
"
\n",
" \n",
" | 2001 | \n",
" Ford | \n",
" 12 | \n",
"
\n",
" \n",
" | GM | \n",
" 13 | \n",
"
\n",
" \n",
" | 2002 | \n",
" Ford | \n",
" 14 | \n",
"
\n",
" \n",
" | GM | \n",
" 13 | \n",
"
\n",
" \n",
" | 2003 | \n",
" Ford | \n",
" 16 | \n",
"
\n",
" \n",
" | GM | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" Sales | \n",
"
\n",
" \n",
" | Firm | \n",
" Year | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ford | \n",
" 2000 | \n",
" 10 | \n",
"
\n",
" \n",
" | GM | \n",
" 2000 | \n",
" 11 | \n",
"
\n",
" \n",
" | Ford | \n",
" 2001 | \n",
" 12 | \n",
"
\n",
" \n",
" | GM | \n",
" 2001 | \n",
" 13 | \n",
"
\n",
" \n",
" | Ford | \n",
" 2002 | \n",
" 14 | \n",
"
\n",
" \n",
" | GM | \n",
" 2002 | \n",
" 13 | \n",
"
\n",
" \n",
" | Ford | \n",
" 2003 | \n",
" 16 | \n",
"
\n",
" \n",
" | GM | \n",
" 2003 | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" Sales | \n",
"
\n",
" \n",
" | Firm | \n",
" Year | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ford | \n",
" 2000 | \n",
" 10 | \n",
"
\n",
" \n",
" | 2001 | \n",
" 12 | \n",
"
\n",
" \n",
" | 2002 | \n",
" 14 | \n",
"
\n",
" \n",
" | 2003 | \n",
" 16 | \n",
"
\n",
" \n",
" | GM | \n",
" 2000 | \n",
" 11 | \n",
"
\n",
" \n",
" | 2001 | \n",
" 13 | \n",
"
\n",
" \n",
" | 2002 | \n",
" 13 | \n",
"
\n",
" \n",
" | 2003 | \n",
" 15 | \n",
"
\n",
" \n",
"
\n",
"
: \n",
"```\n",
"\n",
"Here, you can see how the lambda function takes inputs and creates output the same way a function does:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"15"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dumb_prog = lambda a: a + 10 # I added \"dumb_prog =\" to name the lambda function and use it\n",
"dumb_prog(5)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"15"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# we could define a fnc to do the exact same thing\n",
"def dumb_prog(a):\n",
" return a + 10\n",
"dumb_prog(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Q2: Why is that lambda there? \n",
"\n",
"A2: We use lambdas when we need a function for a short period of time and when the name of the function doesn't matter. \n",
"\n",
"\n",
" \n",
"In the example above, `[df].groupby('industry').assign(avglev = lambda x: x['lev'].mean() )`, \n",
"1. groupby **splits** the dataframe into groups, \n",
"2. then, within each group, it **applies** a function (here: the mean), \n",
"3. and then returns a new dataframe with one observation for each group (the average leverage for the industry). Visually, this **split-apply-combine**[^ref] process looks like this:\n",
"\n",
"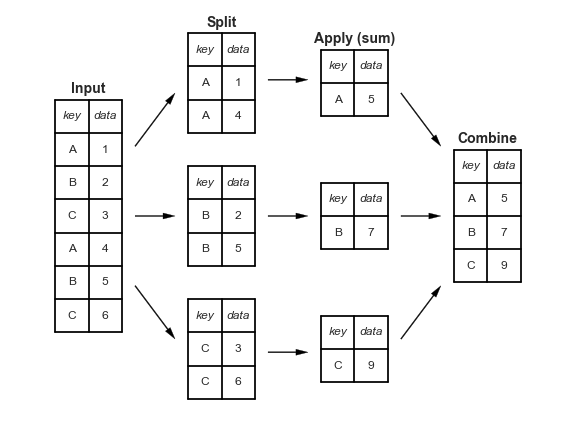\n",
"\n",
"[^ref]: (This figure is yet another resource I'm borrowing from the awesome [PythonDataScienceHandbook](https://jakevdp.github.io/PythonDataScienceHandbook). \n",
"\n",
"But notice! The `.assign()` portion is working on these tiny split up pieces of the dataframe created by `df.groupby('industry')`. Those pieces are dataframe objects that don't have names! \n",
"\n",
"**So lambda functions let us refer to an unnamed dataframe object!** When you type `.assign(newVar = lambda x: someFunc(x))`, `x` is the object (\"some df object\") that assign is working on. Ta da!\n",
"\n",
"```python\n",
"# common syntax within pandas\n",
".assign( = lambda : ) \n",
"\n",
"# often, tempname is just \"x\" for short\n",
".assign( = lambda x: ) \n",
"\n",
"# example:\n",
".assign(lev = lambda x: (x['dltt']+x['dlc'])/x['at'] )\n",
"\n",
"```\n",
"\n",
"```{note}\n",
"It turns out that lambda functions are very useful in python programming, and not just within pandas. For example, some functions take functions as inputs, like [csnap()](#printing-inside-of-chains), `map()`, and `filter()`, and lambda functions let us give them custom functions quickly. \n",
"\n",
"But pandas is where we will use lambda functions most in this class.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## `.transform()` after groupby\n",
"\n",
"Sometimes you get a statistic for a group, but you want that statistic in every single row of your original dataset.\n",
"\n",
"But `groupby` creates a new dataframe that is smaller, with only one row per row.\n",
"\n",
"```{admonition}\n",
":class: tip\n",
"\n",
"Use `.transform()` after `groupby` to \"cast\" those statistics back to the original \n",
"\n",
"```\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
"
\n",
" \n",
" | key | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | A | \n",
" 1 | \n",
"
\n",
" \n",
" | A | \n",
" 4 | \n",
"
\n",
" \n",
" | B | \n",
" 2 | \n",
"
\n",
" \n",
" | B | \n",
" 5 | \n",
"
\n",
" \n",
" | C | \n",
" 3 | \n",
"
\n",
" \n",
" | C | \n",
" 6 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
"
\n",
" \n",
" | key | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | A | \n",
" 5 | \n",
"
\n",
" \n",
" | B | \n",
" 7 | \n",
"
\n",
" \n",
" | C | \n",
" 9 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
"
\n",
" \n",
" | key | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | A | \n",
" 5 | \n",
"
\n",
" \n",
" | A | \n",
" 5 | \n",
"
\n",
" \n",
" | B | \n",
" 7 | \n",
"
\n",
" \n",
" | B | \n",
" 7 | \n",
"
\n",
" \n",
" | C | \n",
" 9 | \n",
"
\n",
" \n",
" | C | \n",
" 9 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
" groupsum | \n",
"
\n",
" \n",
" | key | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | A | \n",
" 1 | \n",
" 5 | \n",
"
\n",
" \n",
" | A | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | B | \n",
" 2 | \n",
" 7 | \n",
"
\n",
" \n",
" | B | \n",
" 5 | \n",
" 7 | \n",
"
\n",
" \n",
" | C | \n",
" 3 | \n",
" 9 | \n",
"
\n",
" \n",
" | C | \n",
" 6 | \n",
" 9 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
" ones | \n",
"
\n",
" \n",
" \n",
" \n",
" | max | \n",
" 6.0 | \n",
" 1 | \n",
"
\n",
" \n",
" | min | \n",
" 1.0 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data | \n",
" ones | \n",
" twos | \n",
" threes | \n",
"
\n",
" \n",
" \n",
" \n",
" | count | \n",
" 6.000000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | mean | \n",
" 3.500000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | std | \n",
" 1.870829 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | min | \n",
" 1.000000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | 25% | \n",
" 2.250000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | 50% | \n",
" 3.500000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | 75% | \n",
" 4.750000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | max | \n",
" 6.000000 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
"
\n",
"